

ZeroEval Launches: Build Self-Improving Agents



"Evaluate and optimize your AI agents using human feedback."
TL;DR: ZeroEval is a tool that helps you build reliable AI agents through evaluations that learn from their mistakes and get better over time.
https://www.youtube.com/watch?v=hSkpdHE7mCs
Founded by Jonathan Chávez & Sebastian Crossa
They met during their first year of college in Mexico over 7 years ago. During that time they worked on side projects together, joined a leading fintech startup as first engineers and most recently built llm-stats.com, a leading LLM leaderboard website that reached 60k MAU and ⅓ million unique users since its launch a few months ago.
- Sebastian was founding engineer at Micro building the future of email (backed by a16z), as well as founding engineer at Atrato (YC W21).
- Jonathan was an early employee on the LLM observability team at Datadog. He did undergrad research on vision transformers for particle physics and RL for robotics.
Foundational models have transformed the world. They are building the second line of offense to fill their capability gaps and create AI products that actually work. They are determined to build the engine behind self-improving software for the following decades.

The problem
Evaluating complex AI systems is hard and time consuming. The more complex your agents get, the harder this issue becomes. This is especially the case when building:
- Long-running, multi-turn agents with dozens of intermediate tool calls
- Agents where you want to measure the quality of images, video, generated UI, audio, personality, taste, etc
Current offline eval methods are high-friction, a lot of work is needed to continuously curate labeled data and write experiments and evaluators.
On the other hand, current LLM judges are static and often have terrible performance, they lack context on how they fail and the nuances of the task at hand.
Your AI agents are as good as your evals. Without them, surpassing the quality threshold your product needs will feel like a never-ending task.
What they are building
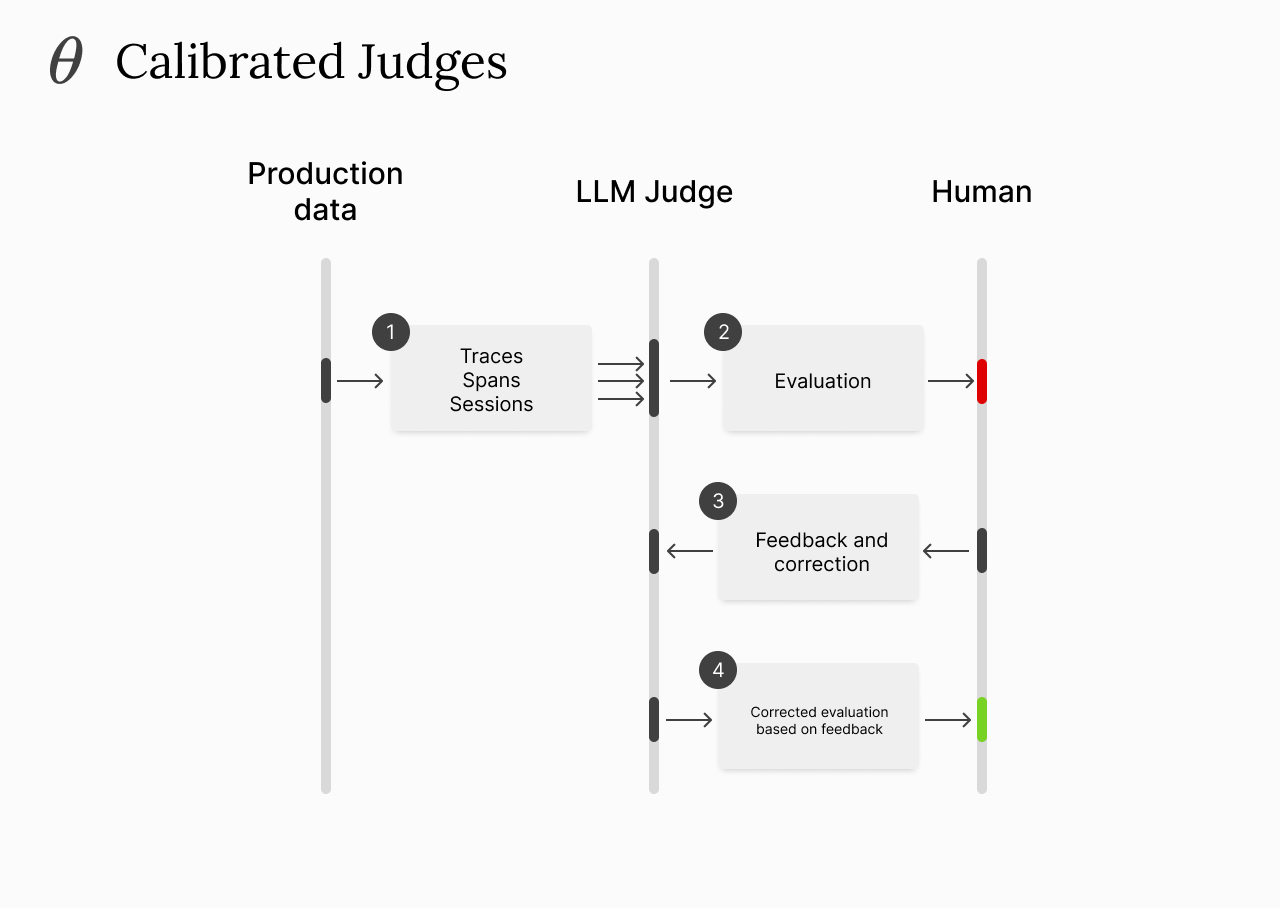
A way to create calibrated LLM judges that get better over time the more production data they see and the more incorrect samples are labeled. The more you teach it on where it's failing, the more reliable it becomes.
Once you have a judge that matches the human preference baseline, you can continue using it on production data or in offline experiments.
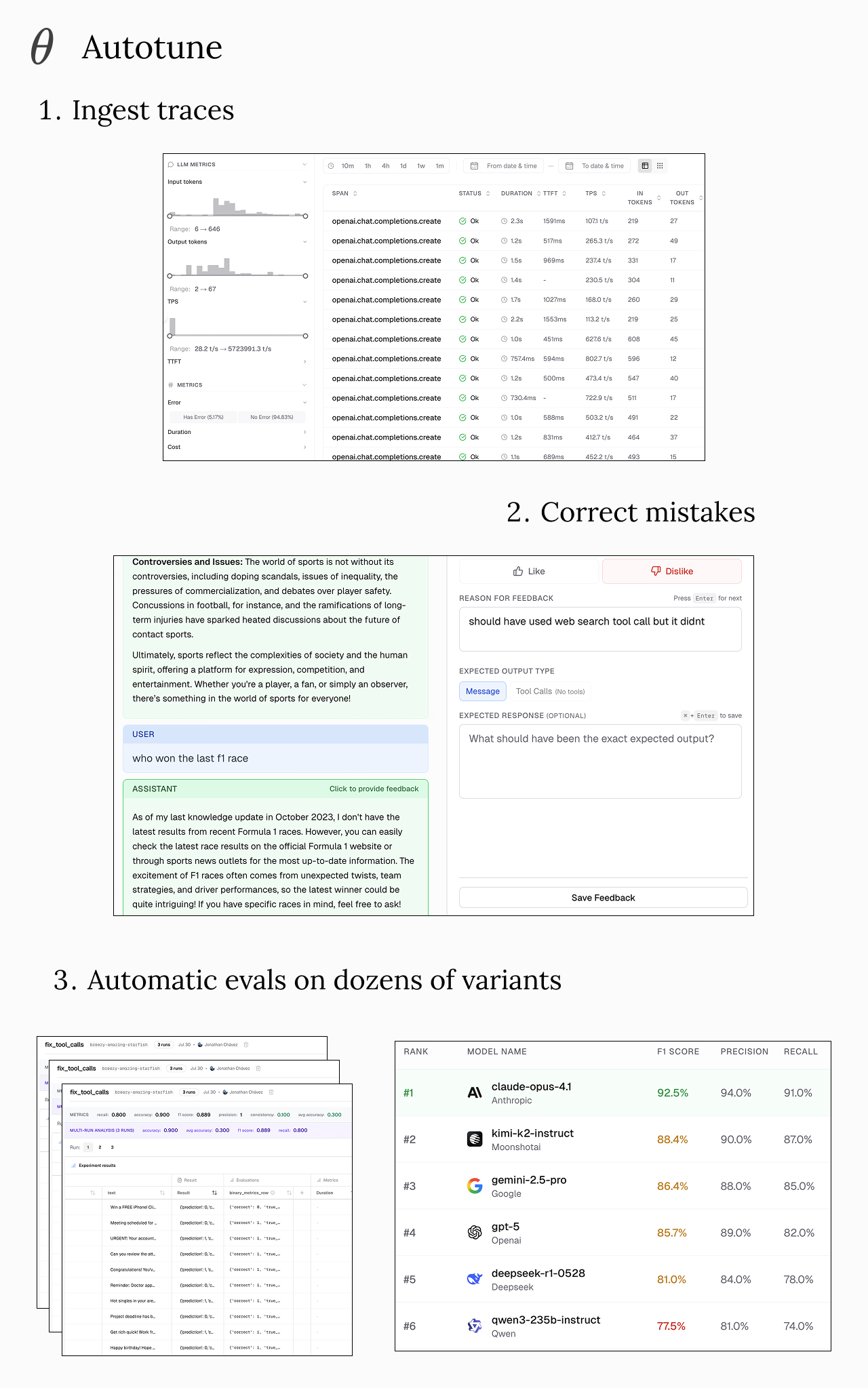
They are also introducing Autotune, a way to do automatic evaluation on dozens of models and prompt optimization based on a few human samples.
They envision a future where AI software improves based on human feedback, where developers define the evaluation criteria as a starting point and errors back propagate to find the optimal implementation.
Their ask
If you have AI agents in production and are struggling to measure their quality and/or achieve the reliability needed for your product's success, the team would love to chat!
They don't just deliver a tool, but will sit with you to understand your pain points and help you build high quality evals.
Reach out here or book a demo.
Learn More
🌐 Visit zeroeval.com to learn more.
🤝 Reach out here or book a demo.
🌟 Give ZeroEval a star on Github.
👣 Follow ZeroEval on LinkedIn & X.


Simplify Startup Finances Today
Take the stress out of bookkeeping, taxes, and tax credits with Fondo’s all-in-one accounting platform built for startups. Start saving time and money with our expert-backed solutions.
Get Started
.png)








