


Vectorview launches evaluation of the capabilities of AI 🤖


Vectorview recently launched!

"Custom task evaluators that red team for safety and benchmark performance"
Vectorview makes it easy to evaluate the capabilities of foundation models and LLM agents. They do this by building custom task evaluators that red team for safety and benchmark performance.
Founded by Emil Fröberg & Lukas Petersson
Problem: Sometimes, LLMs act in ways we didn't intend 🤷
It’s difficult to prevent unwanted behaviors in LLMs due to their non-deterministic nature. Testing them against every possible scenario is hard, making it tough to catch all unintended behaviors. Additionally, most evaluation benchmarks (like MMLU or BBQ) are too general, missing the specific issues that can arise in real-world use. Take this example:

This issue isn’t limited to chatbots. It spans across LLM agents designed for specialized tasks and extends to AI labs striving for model safety. The task of crafting, deploying, and precisely scoring custom evaluations is complex and time-consuming.
Solution: Enabling access to custom evaluations 🔓
Each use case demands a custom evaluation. In the case of the Chevrolet chatbot, Vectorview's custom auto-red teaming solution could be implemented to prevent the mistake.

The platform offers a suite of custom evaluation tools designed to benchmark AI applications against specific, real-world scenarios they are likely to encounter. This targeted approach ensures that AI behaves as intended, mitigating the risk of unintended behaviors that generic benchmarks often miss.
Learn More
🌐 Visit vectorview.ai to learn more
📅 Schedule time for a demo directly here
🤝 Are you working with LLM agents or foundation models? If you need custom evaluations specific to your use case - the Vectorview team can help!
👥 Follow Vectorview on LinkedIn & X

Simplify Startup Finances Today
Take the stress out of bookkeeping, taxes, and tax credits with Fondo’s all-in-one accounting platform built for startups. Start saving time and money with our expert-backed solutions.
Get Started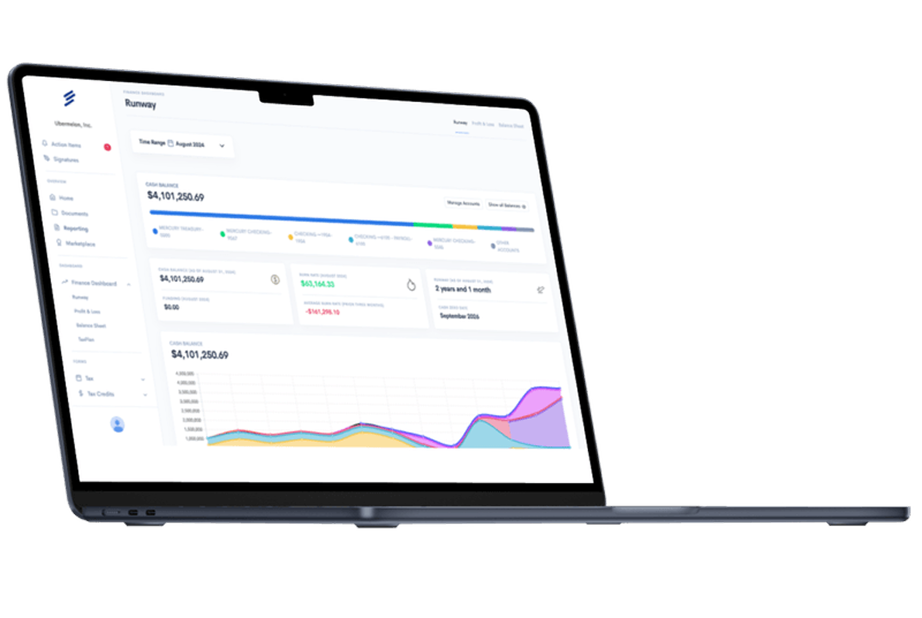
.png)








