


Discover Artie, the real-time data streaming platform for databases and data warehouses. Eliminate data latency and reduce costs by 50%. Easy setup, no programming required. Perfect for engineers and cost-conscious companies. Learn more on the Artie website!


Artie launched on Y Combinator's "Launch YC" this week!

"Real-time data streaming for databases and data warehouses"
Artie transfers data from databases to data warehouses in real-time with CDC streaming.
Founded by Jacqueline Cheong & Robin Tang — they're on a mission to eliminate data latency and make it easy for every company to enable real-time data streaming!
Jacqueline was previously a software investor and was responsible for a ~$300M software book within a larger TMT portfolio. Robin is a software engineer with a background in distributed systems and designing for high throughput and low latency. Prev Consumer and Growth @ Opendoor, built Sunshine CRM @ Zendesk and lead engineer @ Outbound (YC W15).
HOW IT WORKS
Artie is an open-source, streaming version of Fivetran - they transfer data from databases to data warehouses in real-time. Setting up a connector takes minutes and Artie leverages change data capture (CDC) to help companies reduce their data warehouse costs by 50%! This enables organizations to unlock real-time insights for better decision making.
Data is typically synced from production databases to the data warehouse once every X hour(s)/day(s) - this is a constraint that companies have lived with for decades. Robin personally felt the pain of not having access to production data in real-time and there were no easy to use out-of-the-box solutions, so the team decided to build one!
❌ The Problem
Does your company sync data to the data warehouse every 6 hours, or worse, once a day? Are your analytics always lagged and filled with stale insights? Why settle for a data platform that’s barely good enough when you can have real time data AND reduce your data warehouse costs?! Not to mention you can have Artie set up in minutes!
Traditional ETLs are based on batched processes that operate on a cron schedule (DAGs, Airflow) and cannot achieve real-time data syncs.
Building and managing streaming data pipelines is hard. Most companies have a small team of data engineers and they often spend all day maintaining their data pipelines, which is not productive.
Factors companies should consider if they want to self-manage pipelines 👇
🔵 Can the solution scale to multiple different data sources?
- How easy is it to add new data sources?
- How easy is it to manage across all the data sources?
🔵 Can the solution scale to handle 1m+ queries per second?
- Is the solution horizontally scalable?
- Do workers require coordination? Or are they stateless and distributed?
🔵 How do you ensure there are no out of order or missing events (even when the system crashes)?
🔵 Can the solution handle schema evolution without creating breaking changes downstream?
🎉 Solution
Artie leverages change data capture (CDC) and stream processing to achieve sub-minute data latency (~typically 10-20 seconds). Since they only transfer changed data, Artie is more efficient than traditional ETLs and can help you cut down on your data warehouse cost by 50%!
Setting up a connector requires no programming. Just follow the setup guide and deploy in minutes! After the initial snapshot, any changes in your database will be reflected in your data warehouse in real-time.

🎯 Who Needs Artie?
✅ Engineers that are exhausted stitching together Airflow + AWS Glue + Apache Spark + AWS Kinesis/Kafka + Apache Flink 😵💫
✅ Companies that are using traditional ETLs or batched processes. Once you enable real-time, there is no going back (your data engineers/BI analysts won’t let you)! Think of all the previously unattainable use cases that you can now implement without data latency.
✅ Companies that have a cost cutting initiative. Adopt Artie’s CDC streaming capabilities to reduce your data warehouse costs!
LEARN MORE
🌐 Visit www.artie.so to learn more!
🚀 Sign up for Artie here!
⭐ Want to use open source? Install Artie on Github (give them a ⭐!)
🐦🔗 Follow Artie on Twitter & LinkedIn

Simplify Startup Finances Today
Take the stress out of bookkeeping, taxes, and tax credits with Fondo’s all-in-one accounting platform built for startups. Start saving time and money with our expert-backed solutions.
Get Started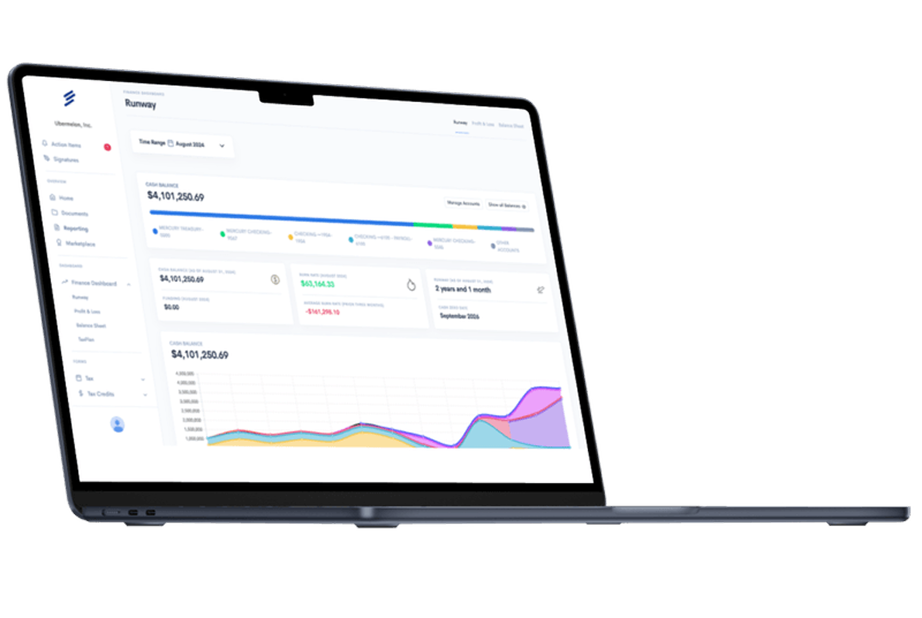
.png)








